Accepted to TMLR with featured and reproducibility certifications, Dec. 2024.
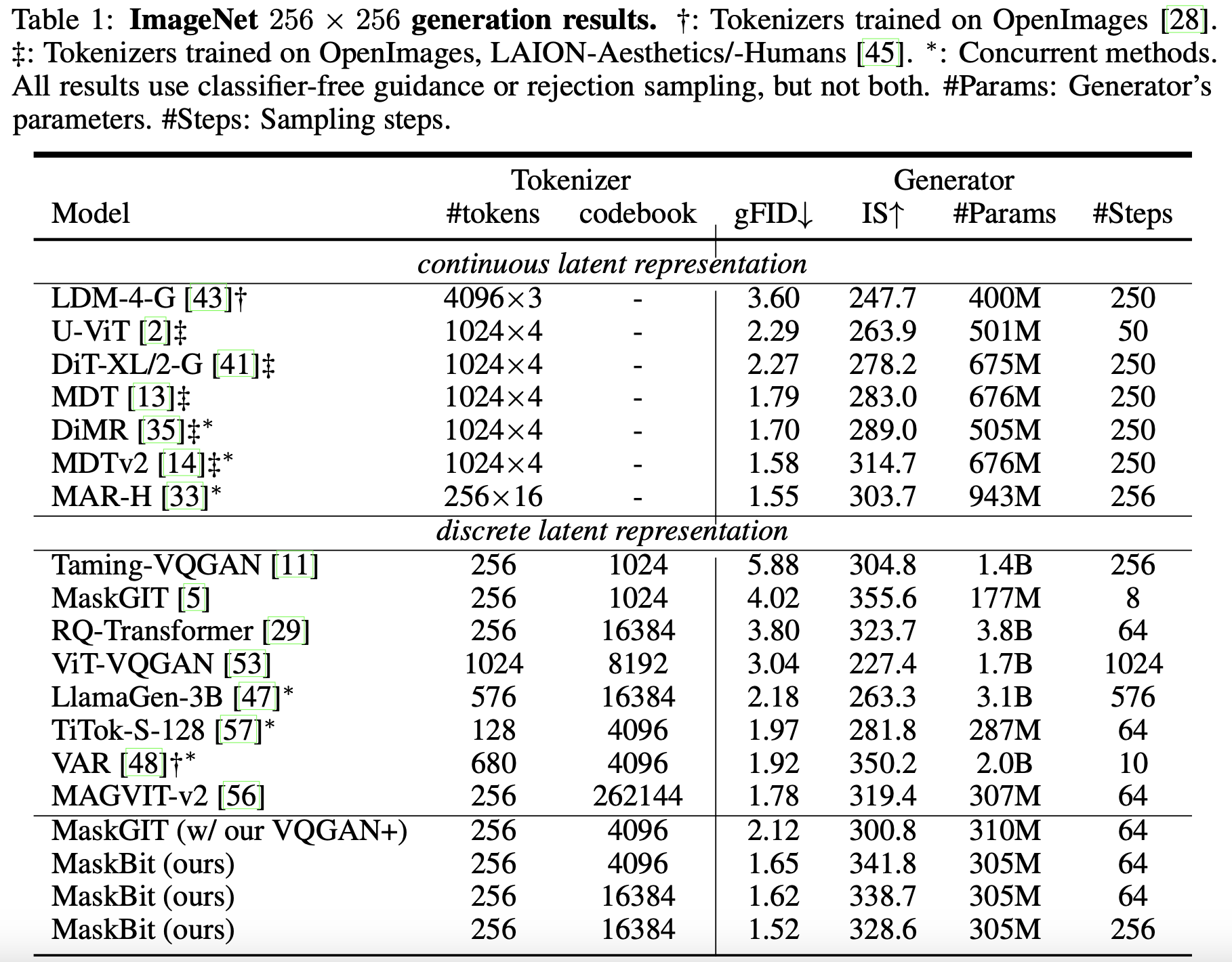
1. We study the key ingredients of recent closed-source VQGAN tokenizers and develop a publicly available, reproducible, and high-performing VQGAN model, called VQGAN+, achieving a significant improvement of 6.28 rFID over the original VQGAN developed three years ago.
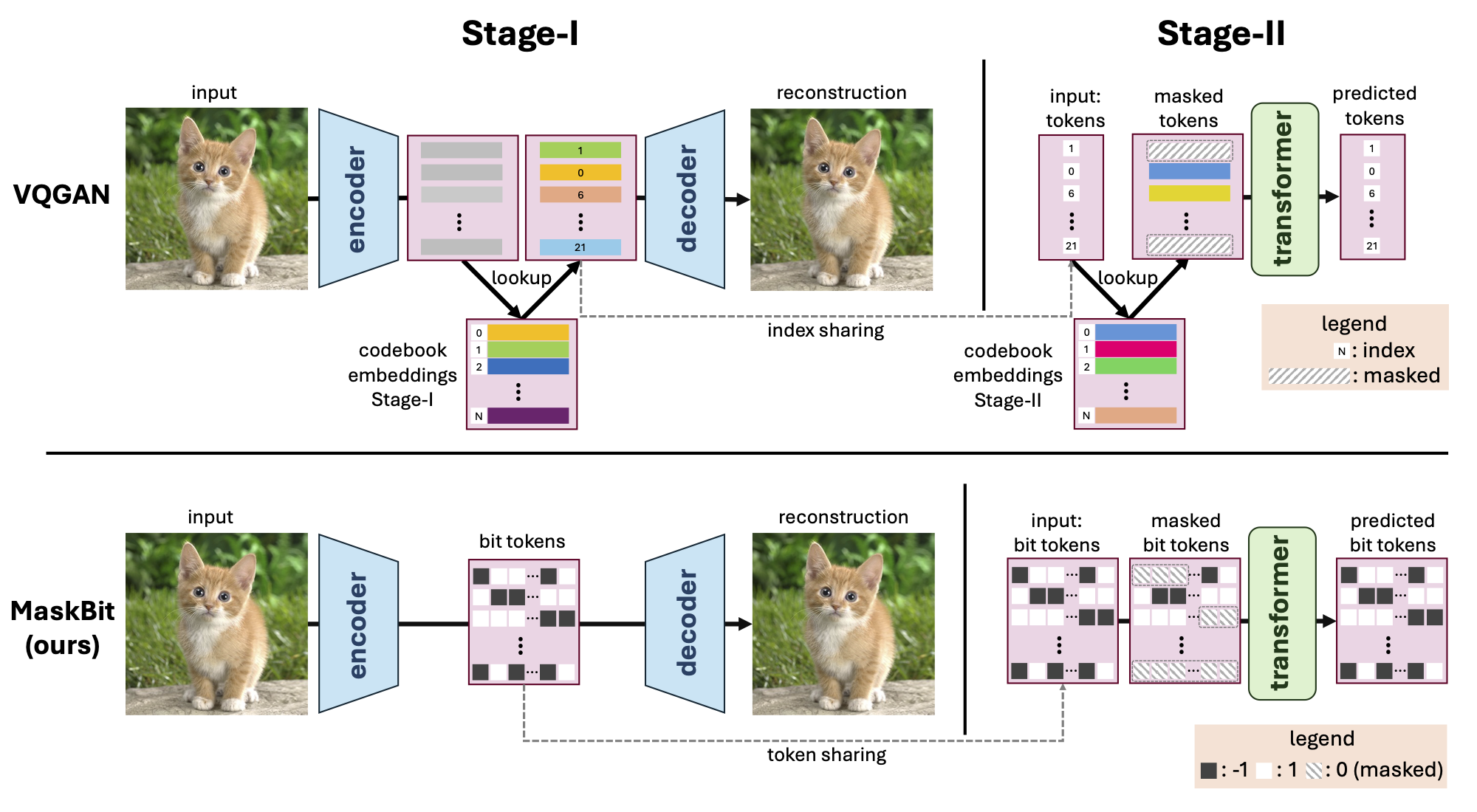
2. Building on our improved tokenizer framework, we leverage modern Lookup-Free Quantization (LFQ). We analyze the latent representation and observe that embedding-free bit token representation exhibits highly structured semantics.
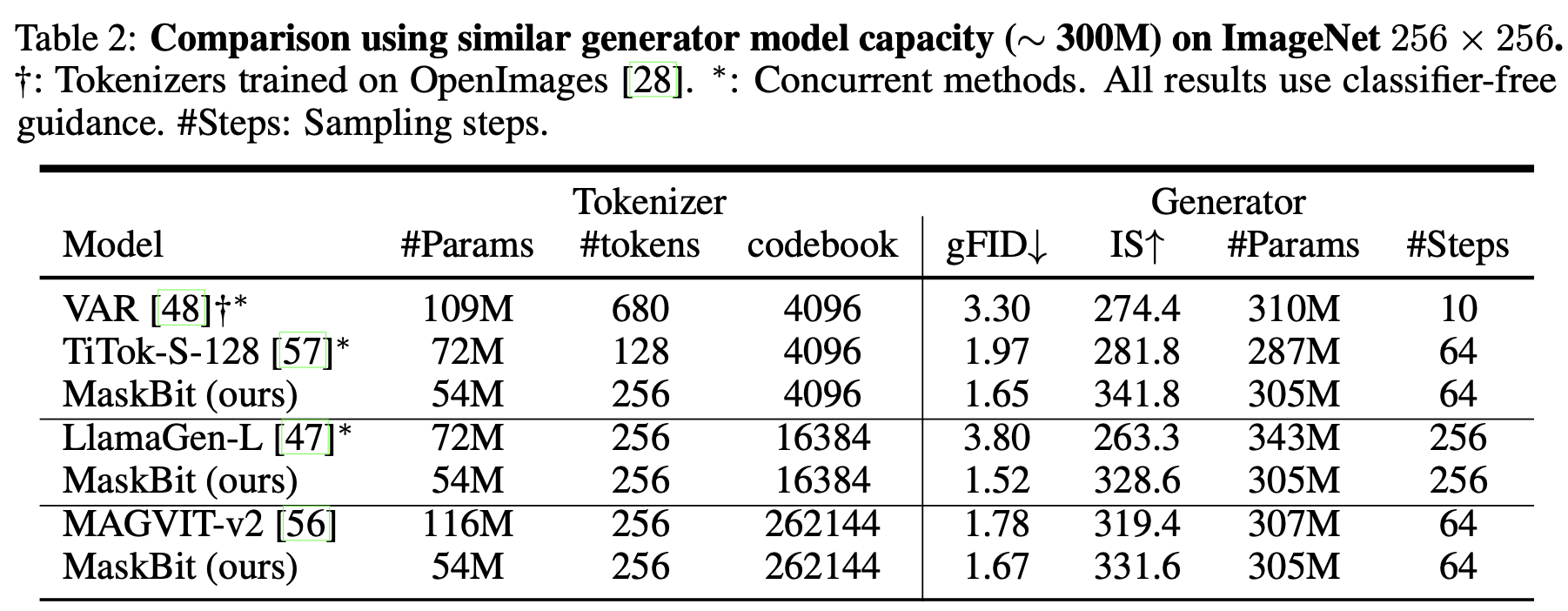
3. Motivated by these discoveries, we develop a novel embedding-free generation framework, MaskBit, which builds on top of the bit tokens and achieves state-of-the-art performance on the ImageNet 256×256 class-conditional image generation benchmark.
Masked transformer models for class-conditional image generation have become a compelling alternative to diffusion models. Typically comprising two stages - an initial VQGAN model for transitioning between latent space and image space, and a subsequent Transformer model for image generation within latent space - these frameworks offer promising avenues for image synthesis. In this study, we present two primary contributions: Firstly, an empirical and systematic examination of VQGANs, leading to a modernized VQGAN. Secondly, a novel embedding-free generation network operating directly on bit tokens -- a binary quantized representation of tokens with rich semantics. The first contribution furnishes a transparent, reproducible, and high-performing VQGAN model, enhancing accessibility and matching the performance of current state-of-the-art methods while revealing previously undisclosed details. The second contribution demonstrates that embedding-free image generation using bit tokens achieves a new state-of-the-art FID of 1.52 on the ImageNet 256×256 benchmark, with a compact generator model of mere 305M parameters.
@article{weber2024maskbit,
author = {Mark Weber and Lijun Yu and Qihang Yu and Xueqing Deng and Xiaohui Shen and Daniel Cremers and Liang-Chieh Chen},
title = {MaskBit: Embedding-free Image Generation via Bit Tokens},
journal = {arXiv:2409.16211},
year = {2024}
}


